Crafting memory allocators

It’s hard to overstate the importance of memory allocators. Without them, programs simply wouldn’t work. One essential step in optimizing code is using custom memory allocators.
There are many different ones available – like
By simply linking your program with one of these allocators, you can almost effortlessly improve performance. These allocators provide fast allocations and deallocations, good memory locality, all of which significantly impact program performance. However, there’s no such thing as a free lunch; sometimes, using custom allocators can lead to increased memory usage or, worse, memory fragmentation. Therefore, choosing a memory allocator always involves some compromise.
In this post, I’d like to discuss how to build a memory allocator. While it will be relatively simple compared to existing solutions, understanding how to create even such a basic allocator provides essential insight into what allocators are and why they’re necessary.
The Simple Allocator
All the code written below is built and tested using Clang 15 with C++17 on macOS Sonoma.
However, it can be easily adapted for C++11 on any C++ compiler and operating system.
I will call it The Simple Allocator. The Simple Allocator can be used in various ways:
- Manual memory allocations and deallocations,
- Overriding standard malloc’s behavior,
- Using in STL containers.
However, The Simple Allocator has limitations:
- Single-threaded,
- Allocated memory must be pre-allocated, for example, on the heap, on the stack, .data segments, .BSS segment, or via mmap,
- Potential fragmentation with long-term use.
These limitations can be relaxed or eliminated, but it will complicate the implementation. Later, when the allocator is ready, I’ll revisit these points.
As for The Simple Allocator beneficial properties, I would highlight:
- Pointers aligned to 16 bytes, customizable if needed,
- Good memory locality,
- On average, it will be faster than the standard malloc implementation.
Naive implementation
Let’s start from the naive implementation.
Allocator alignment
As mentioned earlier, the allocator returns pointers aligned to 16 bytes, which can be parameterized. The parametrization can be done in several ways:
- As a compile-time class template parameter,
- As a runtime class constructor parameter,
- Or simply as a constexpr or
#defineconstant.
Utilizing template or runtime parameters offers flexibility but complicates the implementation unnecessarily. Thus, I prefer to define the allocator alignment as a constant. However, it would be relatively easy to rework it into a parameter if needed.
1
2
3
4
5
class SimpleAllocatorTraits {
public:
static constexpr size_t ALIGNMENT = 16;
static_assert(ALIGNMENT && ((ALIGNMENT - 1) & ALIGNMENT) == 0, "power of 2 is expected");
};
The alignment must be a power of two.
Programs on x86-64 operating systems may not work properly if the alignment is less than 16.
We also need a couple of helper functions that align the sizes and the pointers.
1
2
3
4
5
6
7
8
9
10
template<size_t N, class T>
constexpr T AlignN(T v) noexcept {
static_assert(N && ((N - 1) & N) == 0, "power of 2 is expected");
return static_cast<T>((static_cast<uint64_t>(v) + N - 1) & (~(N - 1)));
}
template<size_t N, class T>
constexpr std::pair<T *, T *> AlignBuffer(T *begin, T *end) noexcept {
return {reinterpret_cast<T *>(AlignN<N>(reinterpret_cast<uintptr_t>(begin))), reinterpret_cast<T *>(AlignN<N>(reinterpret_cast<uintptr_t>(end) - (N - 1)))};
}
Although they mostly look like creepy bitwise magic, they perform a pretty simple task.
AlignN<N>(integer) returns the value rounded to the next integer aligned to N, for example,
| call | returns |
|---|---|
AlignN<16>(7) | 16 |
AlignN<16>(25) | 32 |
AlignN<16>(32) | 32 |
AlignN<16>(798) | 800 |
AlignBuffer<N>(begin, end) returns the sub-interval for the buffer with pointers aligned to N, for example,
| call | returns |
|---|---|
AlignBuffer<16>((void *)0x7, (void *)0x27) | {0x10, 0x20} |
AlignBuffer<16>((void *)0x27, (void *)0x54) | {0x30, 0x50} |
AlignBuffer<16>((void *)0x1, (void *)0x2) | {0x10, 0x00} |
As you may note, AlignBuffer<N>() doesn’t concern itself with the correctness of the sub-interval. That’s okay; we will check it during usage.
In further parts of the text, when I mention that something is aligned, it means that it is aligned to
SimpleAllocatorTraits::ALIGNMENTbytes.
Allocator memory block
The next important part of the implementation is a class that represents a memory block. Memory blocks are the main primitives used by the allocator for allocating memory.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class MemoryBlock {
public:
constexpr explicit MemoryBlock(size_t size) noexcept: metadata{size} {}
constexpr size_t GetBlockSize() const noexcept { return metadata.size; }
constexpr void SetBlockSize(size_t size) noexcept { metadata.size = size; }
uint8_t *UserMemoryBegin() noexcept { return reinterpret_cast<uint8_t *>(this + 1); }
uint8_t *UserMemoryEnd() noexcept { return UserMemoryBegin() + metadata.size; }
static constexpr MemoryBlock *FromUserMemory(void *ptr) noexcept {
return static_cast<MemoryBlock *>(ptr) - 1;
}
private:
struct alignas(SimpleAllocatorTraits::ALIGNMENT) {
size_t size;
} metadata;
};
Most of the methods are self-explanatory. Let’s discuss how the class is going to be used and why the metadata field needs the explicit alignas specifier.
Let me jump ahead a bit and mention that all MemoryBlock objects are created on aligned pointers. The user doesn’t interact with the MemoryBlock object directly; instead, the user receives a pointer to the allocated memory from MemoryBlock::UserMemoryBegin(), and upon deallocation, the user passes this pointer back to the allocator. We then restore the pointer to the original MemoryBlock using the static method MemoryBlock::FromUserMemory(). Here is a pseudocode example:
1
2
3
4
5
6
7
8
9
void *malloc(size_t size) {
MemoryBlock *memory_block = allocate_memory_block_somehow(size);
return memory_block->UserMemoryBegin();
}
void free(void *ptr) {
MemoryBlock *memory_block = MemoryBlock::FromUserMemory(ptr);
deallocate_memory_block_somehow(memory_block);
}
 MemoryBlock object layout
MemoryBlock object layout
From all this, it follows that if we intend to return the aligned pointer to the user, the MemoryBlock::metadata must also be aligned. Therefore, the explicit alignas specifier is required.
Note that in this implementation, we only store size in the metadata, but it may be more complicated. We can include many other details, such as:
- a flag indicating if the memory has already been deallocated to detect double deallocations,
- a linked list node containing all allocated blocks to detect memory leaks,
- call stacks indicating where the last allocation and deallocation were performed for easier debugging of the issues,
- and so on.
Allocator interface
The class interface is quite trivial:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class SimpleAllocator {
public:
SimpleAllocator() = default;
bool Init(void *buffer, size_t buffer_size) noexcept;
void *Allocate(size_t size) noexcept;
void Deallocate(void *ptr) noexcept;
void *Reallocate(void *ptr, size_t new_size) noexcept;
private:
uint8_t *CutBuffer(size_t size) noexcept;
uint8_t *buffer_begin_{nullptr};
uint8_t *buffer_end_{nullptr};
uint8_t *current_{nullptr};
};
SimpleAllocator::Init
At first glance, the Init() method may appear as follows:
1
2
3
4
5
void SimpleAllocator::Init(void *buffer, size_t buffer_size) noexcept {
buffer_begin_ = static_cast<uint8_t *>(buffer);
buffer_end_ = buffer_begin_ + buffer_size;
current_ = buffer_begin_;
}
The issue with such an implementation is that void *buffer may be an unaligned pointer, and size_t buffer_size may represent an unaligned size. While we could address this concern later, it is much better to maintain the invariant that all pointers in the allocator are aligned from the beginning.
To achieve this, we can use the AlignBuffer<SimpleAllocatorTraits::ALIGNMENT>() method. Here is a revised version of the Init() method.
1
2
3
4
5
6
7
8
9
10
11
12
13
bool SimpleAllocator::Init(void *buffer, size_t buffer_size) noexcept {
if (buffer_begin_ || buffer_end_ || current_) { return false; }
auto being = static_cast<uint8_t *>(buffer);
auto end = being + buffer_size;
auto [buffer_begin, buffer_end] = AlignBuffer<SimpleAllocatorTraits::ALIGNMENT>(being, end);
if (buffer_begin >= buffer_end) { return false; }
buffer_begin_ = buffer_begin;
buffer_end_ = buffer_end;
current_ = buffer_begin_;
return true;
}
The code is pretty straightforward. We pick an aligned sub-buffer and return true in case of successful initialization, false otherwise.
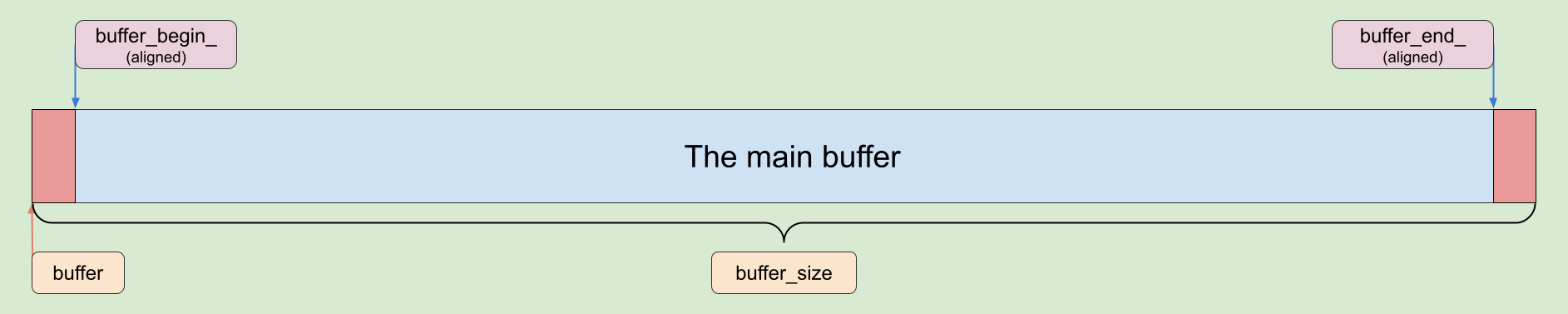 Aligned allocator buffer
Aligned allocator buffer
SimpleAllocator::CutBuffer
Before delving into the details, let’s take a look at another helper private method, CutBuffer():
1
2
3
4
5
6
7
uint8_t *SimpleAllocator::CutBuffer(size_t size) noexcept {
if (current_ + size > buffer_end_) { return nullptr; }
uint8_t *memory_piece = current_;
current_ += size;
return memory_piece;
}
The method cuts the requested size from the allocator buffer and returns a pointer to the beginning of the cut memory. If there is insufficient memory available, it returns nullptr. Note that the method doesn’t concern about alignment.
 Cut allocator buffer
Cut allocator buffer
SimpleAllocator::Allocate
It’s time for allocation. Here is the first and main method, Allocate():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void *SimpleAllocator::Allocate(size_t size) noexcept {
if (!size) {
return nullptr;
}
size = AlignN<SimpleAllocatorTraits::ALIGNMENT>(size);
static_assert(alignof(MemoryBlock) % SimpleAllocatorTraits::ALIGNMENT == 0);
if (uint8_t *memory_piece = CutBuffer(sizeof(MemoryBlock) + size)) {
auto *memory_block = new (memory_piece) MemoryBlock{size};
return memory_block->UserMemoryBegin();
}
return nullptr;
}
The implementation is quite simple:
- Align the allocating size.
- Attempt to cut out a memory segment from the allocator buffer.
- Instantiate a memory block with metadata on the cut memory segment.
- Return the allocated memory using
MemoryBlock::UserMemoryBegin().
One of the most important aspects here is the size aligning. We cut the memory segment with a size of sizeof(MemoryBlock) + size from the aligned buffer. Because MemoryBlock and size are aligned, their sum will also be aligned. Consequently, the current_ pointer will be aligned after cutting the buffer. This ensures that all pointers in the allocator are aligned, maintaining the required invariant.
Also, you may note that even if a user requests 1 byte, the allocator allocates 16 bytes for the user and cuts 32 bytes from the buffer. This could be improved; for example, we could reserve a region in the buffer for small memory blocks with a fixed size of 16 bytes, which don’t have any metadata at all, and use them for small allocations. With this optimization, the allocator still allocates 16 bytes in case the user requests 1 byte, but it will only cut 16 bytes from the buffer. I will not implement this optimization here because I don’t want to overcomplicate the implementation.
This optimization cannot be extended to keep very small memory blocks for 8 bytes and super very small memory blocks for 4 bytes because, in this case, small allocations will return unaligned pointers.
SimpleAllocator::Reallocate
At first glance, Reallocate() can be implemented like this:
1
2
3
4
5
6
7
8
9
void *SimpleAllocator::Reallocate(void *ptr, size_t new_size) noexcept {
auto *new_ptr = Allocate(new_size);
if (ptr && new_ptr) {
auto *memory_block = MemoryBlock::FromUserMemory(ptr);
std::memcpy(new_ptr, ptr, std::min(new_size, memory_block->GetBlockSize()));
Deallocate(ptr);
}
return new_ptr;
}
But this is not efficient.
Here is an example:
1
2
3
void *ptr = allocator.Allocate(2);
// do something
void *new_ptr = allocator.Reallocate(ptr, 8);
Should the allocator do anything here? Actually, no. In this case, the Reallocate() method may simply return the same pointer. The reason is that when allocating 2 bytes, the allocator returns a 16-byte MemoryBlock, and reallocating to 8 bytes actually requests a 16-byte MemoryBlock too, so nothing needs to be done; just return the same pointer to the same memory.
Another interesting case is when the reallocating MemoryBlock is adjusted to the main buffer. In this case, we may simply extend it.
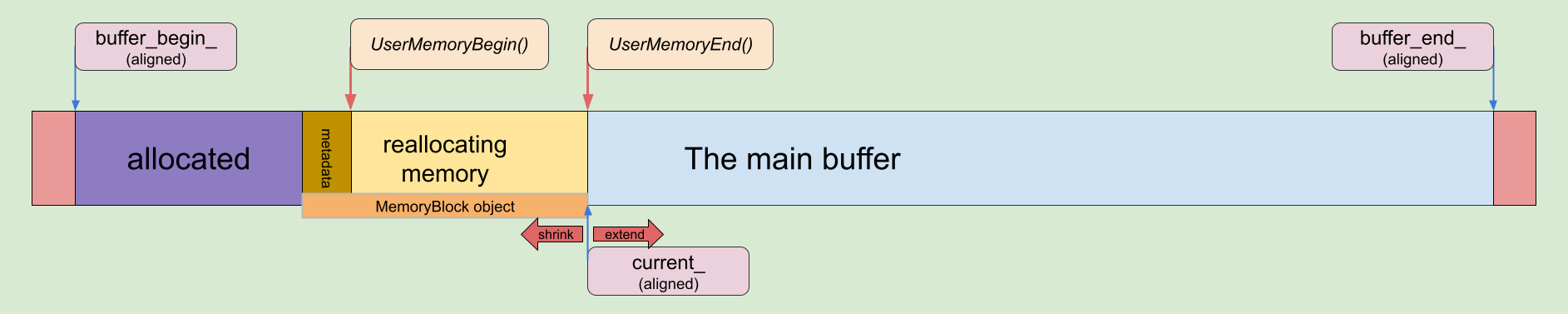 MemoryBlock extending
MemoryBlock extending
Here is the improved implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
void *SimpleAllocator::Reallocate(void *ptr, size_t new_size) noexcept {
if (!ptr) { return Allocate(new_size); }
if (!new_size) { Deallocate(ptr); return nullptr; }
new_size = AlignN<SimpleAllocatorTraits::ALIGNMENT>(new_size);
auto *memory_block = MemoryBlock::FromUserMemory(ptr);
// The old MemoryBlock is suitable for the new size
if (new_size == memory_block->GetBlockSize()) { return ptr; }
// Check if the old MemoryBlock is adjusted to the main buffer
if (memory_block->UserMemoryEnd() == current_) {
if (new_size < memory_block->GetBlockSize()) {
// Return unnecessary memory to the main buffer
current_ -= memory_block->GetBlockSize() - new_size;
memory_block->SetBlockSize(new_size);
return ptr;
}
const size_t extra_size = new_size - memory_block->GetBlockSize();
// Cut extra memory from the main buffer and add it into the old MemoryBlock
if (CutBuffer(extra_size)) {
memory_block->SetBlockSize(new_size);
return ptr;
}
}
auto *new_ptr = Allocate(new_size);
if (new_ptr) {
std::memcpy(new_ptr, ptr, std::min(memory_block->GetBlockSize(), new_size));
Deallocate(ptr);
}
return new_ptr;
}
Interestingly, this implementation is final and will not be changed or optimized later.
SimpleAllocator::Deallocate
The last method is Deallocate():
1
2
3
4
5
6
7
8
void SimpleAllocator::Deallocate(void *ptr) noexcept {
if (!ptr) { return; }
auto *memory_block = MemoryBlock::FromUserMemory(ptr);
if (memory_block->UserMemoryEnd() == current_) {
current_ = reinterpret_cast<uint8_t *>(memory_block);
}
}
In this implementation, the allocator is able to deallocate memory blocks that are only adjusted to the main buffer.
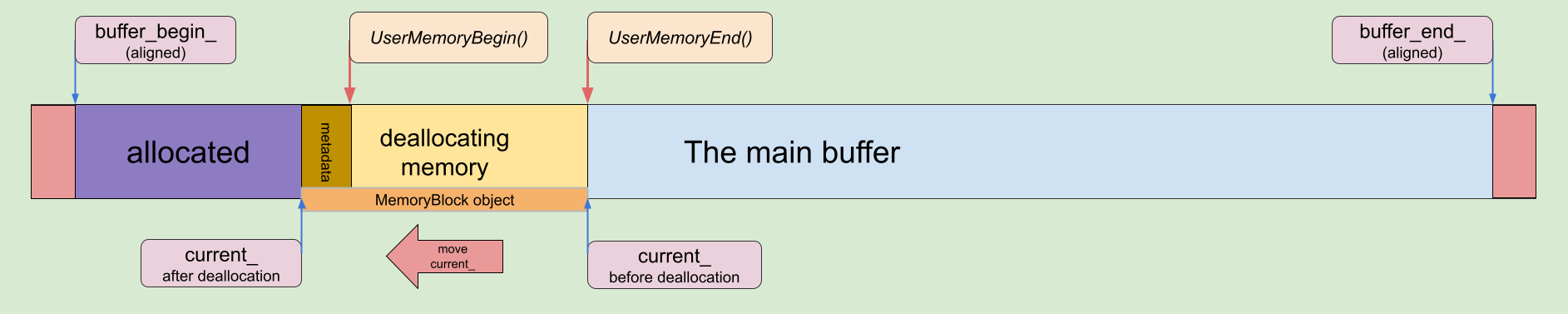 MemoryBlock deallocation
MemoryBlock deallocation
But what should be done with others? For example:
1
2
3
auto *p1 = allocator.Allocate(10);
auto *p2 = allocator.Allocate(12);
allocator.Deallocate(p1);
In the example, p1 is not adjusted to the main buffer. So, what should we do with this and similar pieces of memory?
 MemoryBlock deallocation
MemoryBlock deallocation
Answering this question here, we will proceed to construct the entire allocator. In a sense, an allocator deals with how to reuse the deallocated memory that cannot be returned to the main buffer.
Slabs and Slots
There is a quite efficient and popular way to manage memory, called Slab allocation. I will not use it as is, but I will use the idea.
- Prepare a table which keeps the deallocated memory slots by their sizes.
- The memory slots represent a forward linked list.
- In
Deallocate(), we put the deallocatingMemoryBlockinto the corresponding slot. - In
Allocate(), we check if there is an availableMemoryBlockin the corresponding slot and return it.
MemorySlot
We need a class that represents memory slot list. Here it is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class MemorySlot {
public:
constexpr MemorySlot() = default;
void AddNext(MemoryBlock *memory_block) noexcept {
next_ = new (memory_block->UserMemoryBegin()) MemorySlot{next_};
}
MemoryBlock *GetNext() noexcept {
if (next_) {
auto *next = next_;
next_ = next->next_;
return MemoryBlock::FromUserMemory(next);
}
return nullptr;
}
private:
constexpr explicit MemorySlot(MemorySlot *next) noexcept: next_{next} {}
MemorySlot *next_{nullptr};
};
A few points about the class implementation:
- The
MemorySlotobject is a list node itself. MemorySlot::AddNext()constructs the next node using deallocated user memory. Since everyMemoryBlockhas at leastSimpleAllocatorTraits::ALIGNMENTavailable bytes (after size alignment) of user memory, we can use them to place theMemorySlotobject there.MemorySlot::GetNext()retrieves the next available slot and casts it back to aMemoryBlock.MemoryBlockis not destroyed after being added, and it keeps valid metadata.
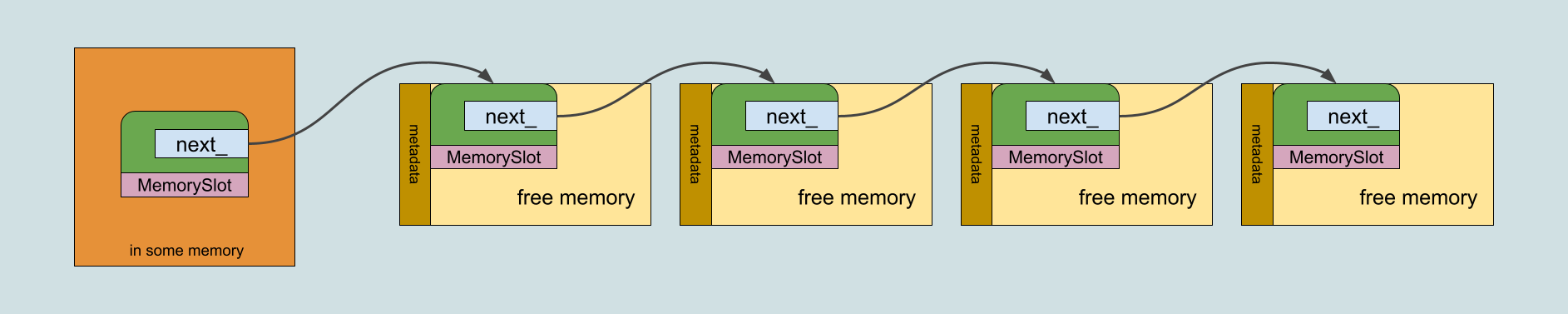 MemorySlot list
MemorySlot list
SimpleAllocator with MemorySlot
Now, let’s add a MemorySlot table to the SimpleAllocator class:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class SimpleAllocatorBase {
private:
static constexpr size_t ConstExprLog2(size_t x) {
return x == 1 ? 0 : 1 + ConstExprLog2(x >> 1);
}
protected:
static constexpr size_t GetSlotIndex(size_t size) noexcept {
constexpr size_t alignment_shift = ConstExprLog2(SimpleAllocatorTraits::ALIGNMENT);
return (size >> alignment_shift) - 1;
}
};
class SimpleAllocator : SimpleAllocatorBase {
public:
// ...
private:
// ...
constexpr static size_t MAX_SLOT_SIZE_{16 * 1024};
std::array<MemorySlot, GetSlotIndex(MAX_SLOT_SIZE_)> slots_{};
};
Why do we need SimpleAllocatorBase? Because in C++, it is not permitted to call static constexpr methods for declarations within the same class. As you may have noticed, GetSlotIndex() is called to calculate the size for the slot table array. Therefore, defining the method in a base class serves as a good workaround for calling a constexpr method.
Let’s take a closer look at the method GetSlotIndex(). This method returns the index in the slot table where the memory slot with the specific size could be retrieved. It is assumed that the size passed into the method is aligned, meaning it is not less than SimpleAllocatorTraits::ALIGNMENT (16 in our case). It is much easier to understand if we take a look at some examples:
| call | returns |
|---|---|
GetSlotIndex(16) | 0 |
GetSlotIndex(32) | 1 |
GetSlotIndex(48) | 2 |
GetSlotIndex(1024) | 63 |
GetSlotIndex(16 * 1024) | 1023 |
So, SimpleAllocator::slots_ represents the slot table with available MemoryBlock objects.
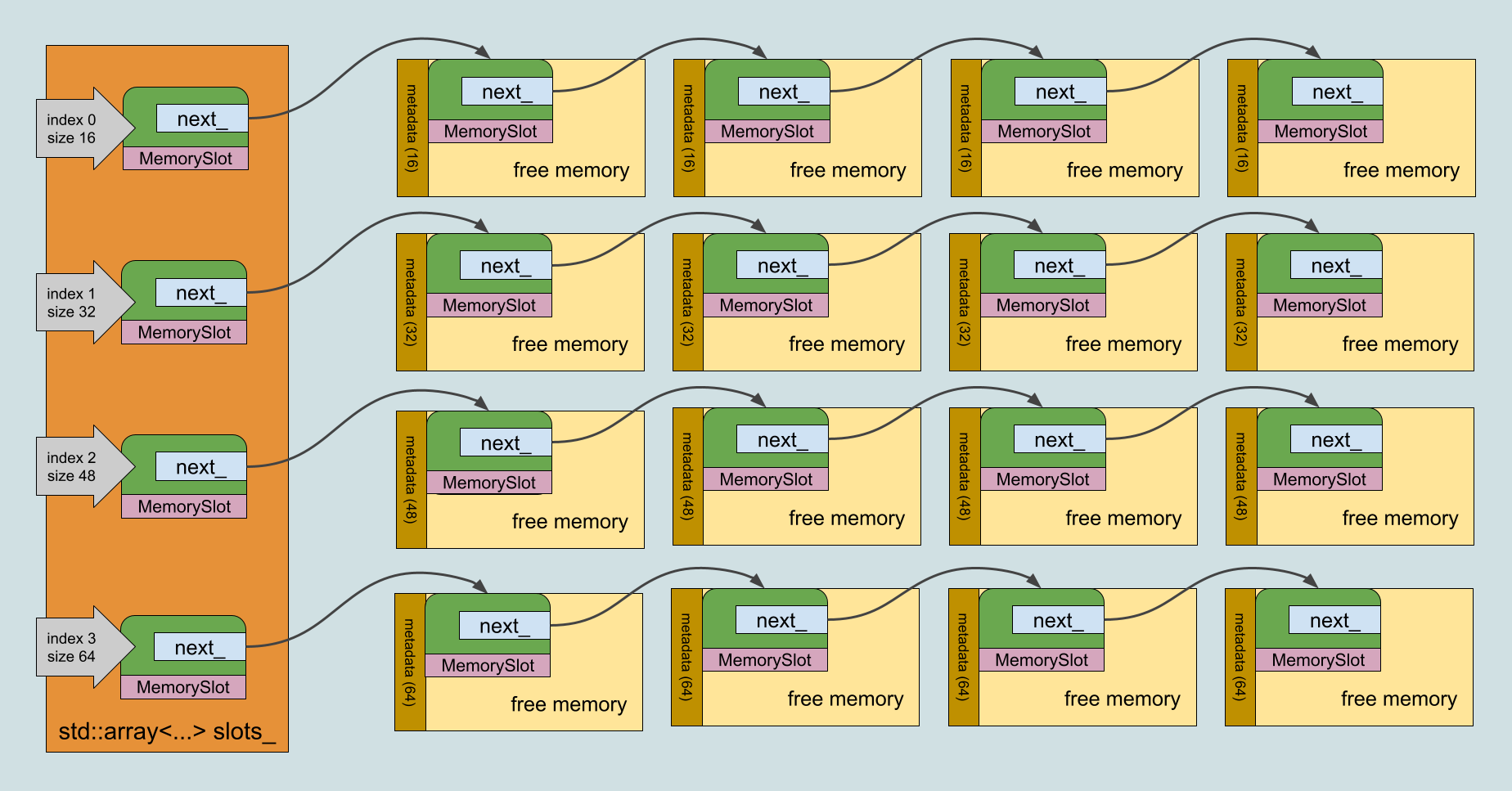 The slot table
The slot table
There is an important aspect to note: the table keeps slots with a size less than SimpleAllocator::MAX_SLOT_SIZE_ bytes. We will discuss later what this means for the allocator.
SimpleAllocator::Deallocate with MemorySlot
Let’s use the memory slot table in the Deallocate() method.
1
2
3
4
5
6
7
8
9
10
11
void SimpleAllocator::Deallocate(void *ptr) noexcept {
// ...
auto *memory_block = MemoryBlock::FromUserMemory(ptr);
// ...
// If possible, extend the main buffer by the memory block and return
// ...
const size_t slot_index = GetSlotIndex(memory_block->GetBlockSize());
if (slot_index < slots_.size()) {
slots_[slot_index].AddNext(memory_block);
}
}
So now if the memory block is not adjusted to the main buffer, we put it into the slot table.
SimpleAllocator::Allocate with MemorySlot
The same idea applies to the Allocate() method: before checking the available size in the main buffer, attempt to obtain a memory block from the slot table.
1
2
3
4
5
6
7
8
9
10
11
12
void *SimpleAllocator::Allocate(size_t size) noexcept {
// ...
const size_t slot_index = GetSlotIndex(size);
if (slot_index < slots_.size()) {
if (MemoryBlock *memory_block = slots_[slot_index].GetNext()) {
return memory_block->UserMemoryBegin();
}
}
// ...
// Allocate from the main buffer
// ...
}
One question remains: the slot table has a fixed size, and we can only use it for storing memory blocks with sizes less than SimpleAllocator::MAX_SLOT_SIZE_ bytes. However, what should be done if the memory block size is greater than or equal to SimpleAllocator::MAX_SLOT_SIZE_ bytes?
The memory tree
The slot table stores a list of memory blocks, all of which have the same specific size. Access to the list is performed by an index, which can be easily calculated, enabling quick access to the required memory block. Consequently, retrieving a memory block from the slot table costs almost nothing. However, this approach has a disadvantage: the slot table has a fixed size, so we cannot keep all sizes in the table. This means we need a data structure suited to the following requirements:
- It can grow dynamically.
- The nodes of the data structure can be constructed directly on a memory block (within freed user memory).
- Fast searching for a memory block suitable for a specific size.
We may try to use a simple forward list; it perfectly fits the first two requirements. However, the problem lies in searching for a suitable memory block in a forward list, which is a linear operation with O(N) runtime, making it very slow.
Instead, we may consider using a binary tree with the memory block size as a node key. This structure can be dynamically grown, and tree nodes can be constructed using deallocated memory. Most importantly, we can perform lookups for the suitable memory block with a runtime of O(log(N)), which is efficient.
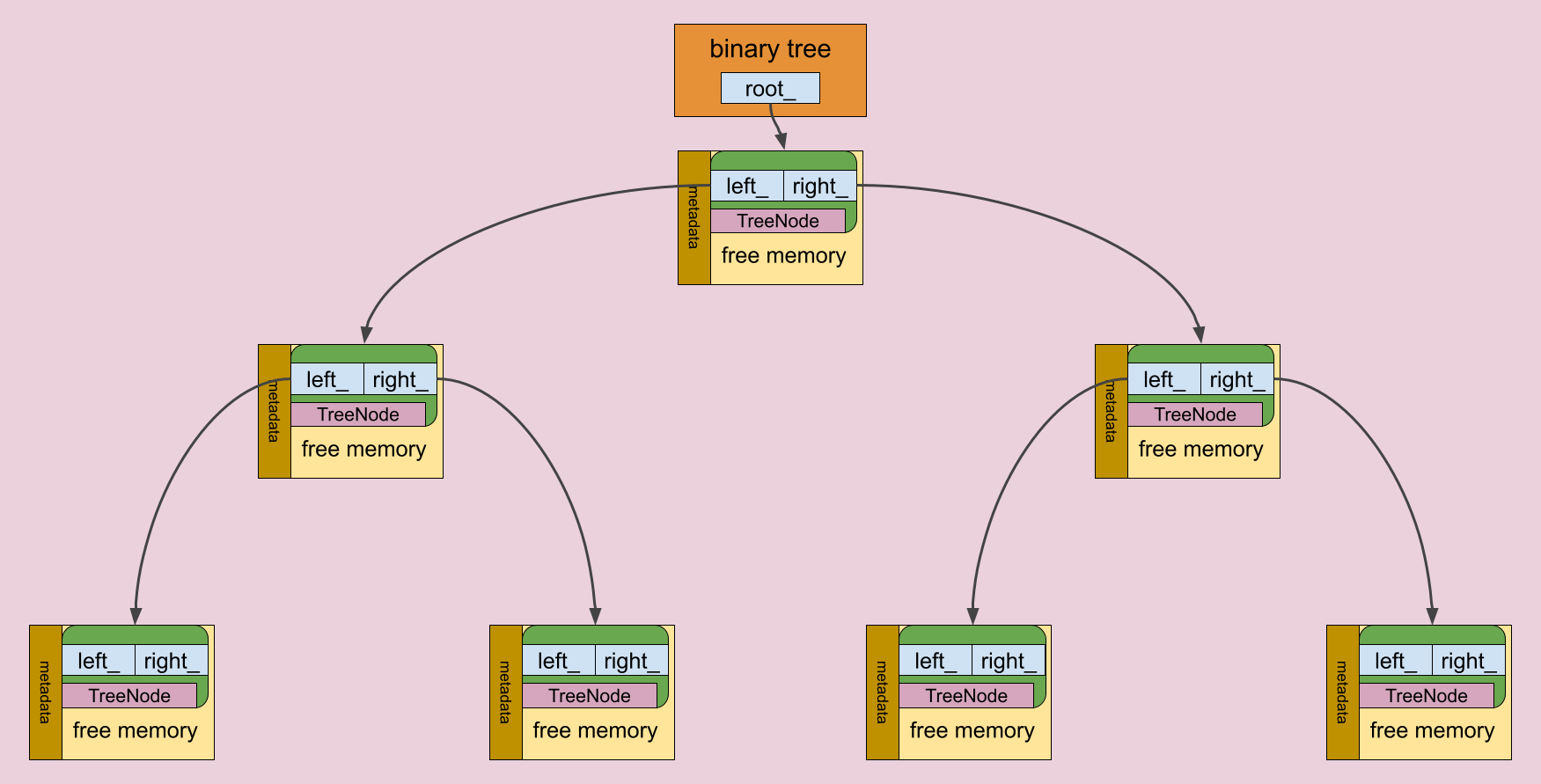 The memory tree
The memory tree
Additionally, this tree could be optimized. We could use a tree node as a head for a linked list that stores nodes with the same sizes.
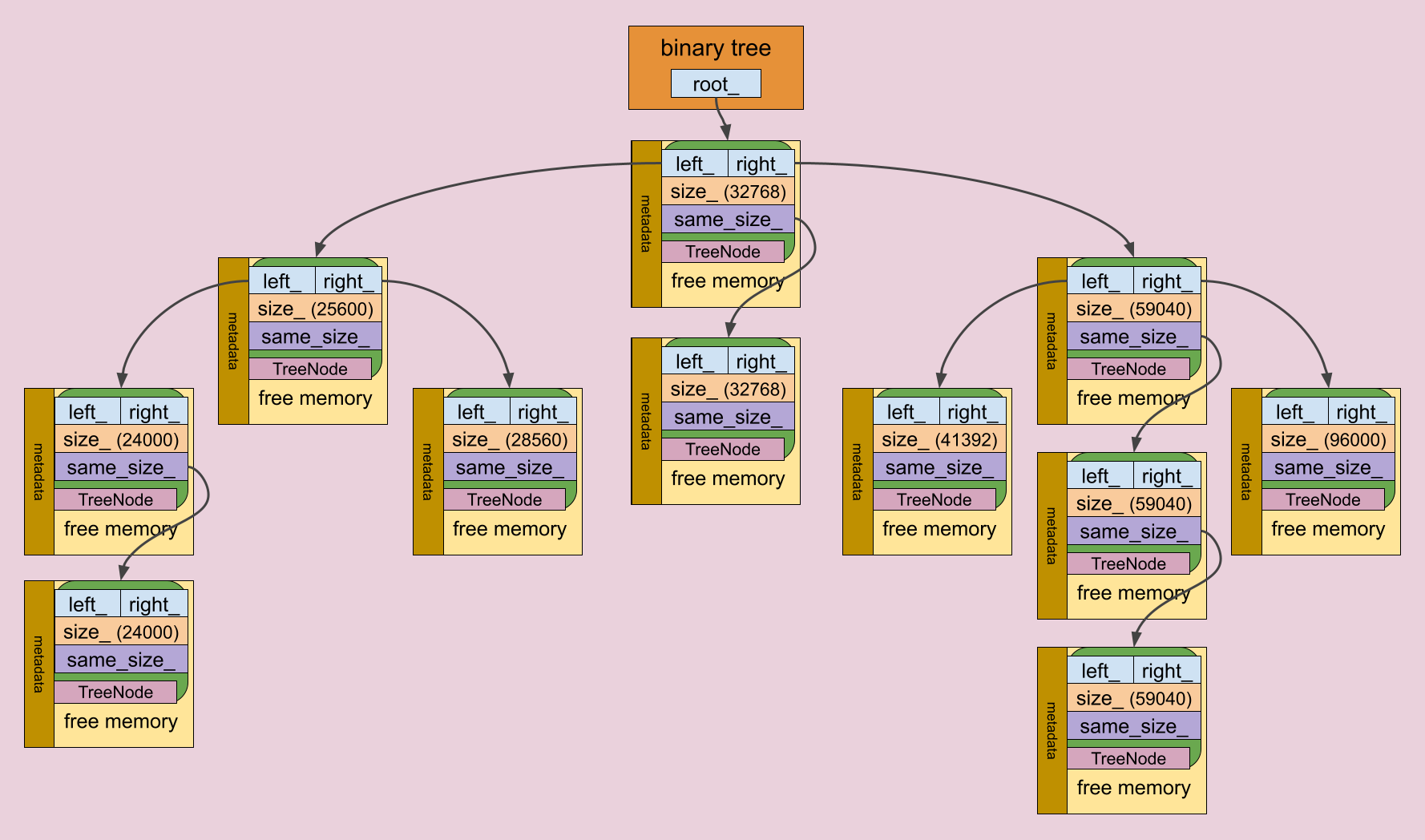 The memory tree combined with linked lists
The memory tree combined with linked lists
Using a binary tree requires attention to tree balancing, as lookup in an unbalanced tree is a linear operation. There are several methods for balancing a tree, such as
- Red-Black trees,
- AVL trees,
- and others.
AVL trees and Red-Black trees are very similar. The main differences are that AVL trees have faster search speed because they are more balanced where Red-Black trees have better insert and remove speed. During allocation, we need to search for the node and remove it from the tree. During deallocation, we need to search for the parent and insert the node into the tree. Since insertion and removal are performed with every tree access, I decided to use a Red-Black tree. However, I haven’t conducted any benchmarks; therefore, feel free to try an AVL tree or any other alternatives.
Implementing a Red-Black tree or an AVL tree can be challenging. However, you can easily find many ready-made implementations on the internet, including on Wikipedia: Red-black tree and AVL tree.
Here is the Red-Black tree implementation for The Simple Allocator: MemoryTree.h and MemoryTree.cpp. I do not post the full implementation here since it consists of hundreds of lines of non-trivial code, which isn’t directly related to the allocator.
MemoryTree
Let’s start with the MemoryTree::TreeNode class, which represents a Red-Black tree node.
1
2
3
4
5
6
7
8
9
10
11
class MemoryTree::TreeNode {
public:
TreeNode *left{nullptr};
TreeNode *right{nullptr};
TreeNode *parent{nullptr};
enum { RED, BLACK } color{RED};
size_t block_size{0};
TreeNode *same_size_nodes{nullptr};
// methods..
};
Skipping the fields related to the tree, we’re interested in two other fields:
MemoryTree::TreeNode::block_size: the size of the memory block associated with this node.MemoryTree::TreeNode::same_size_nodes: a linked list that stores nodes with the same sizes.
We could technically remove
MemoryTree::TreeNode::block_sizeand utilize the size fromMemoryBlock::metadata, but this would overcomplicate the code without providing any benefits. Therefore, I decided to duplicate the size into the tree node.
Here are the public methods of the class MemoryTree:
1
2
3
4
5
6
7
8
class MemoryTree {
public:
void InsertBlock(MemoryBlock *memory_block) noexcept;
MemoryBlock *RetrieveBlock(size_t size) noexcept;
private:
// ...
};
MemoryTree::InsertBlock
The MemoryTree::InsertBlock method inserts a deallocated memory block into the tree. Here is the implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
void MemoryTree::InsertBlock(MemoryBlock *memory_block) noexcept {
const size_t size = memory_block->GetBlockSize();
assert(sizeof(TreeNode) <= size);
TreeNode *new_node = new (memory_block->UserMemoryBegin()) TreeNode{size};
if (!root_) {
new_node->color = TreeNode::BLACK;
root_ = new_node;
return;
}
TreeNode *parent = LookupNode(size, false);
if (parent->block_size == size) {
new_node->same_size_nodes = parent->same_size_nodes;
parent->same_size_nodes = new_node;
return;
}
new_node->parent = parent;
if (size < parent->block_size) {
parent->left = new_node;
} else {
parent->right = new_node;
}
FixRedRed(new_node);
}
Let’s highlight the most interesting lines.
- Create a
TreeNodeusing deallocated user memory for insertion into the tree.
1
TreeNode *new_node = new (memory_block->UserMemoryBegin()) TreeNode{size};
- If the memory block has the same size as the parent node, add the new node to the linked list.
1
2
3
4
5
if (parent->block_size == size) {
new_node->same_size_nodes = parent->same_size_nodes;
parent->same_size_nodes = new_node;
return;
}
MemoryTree::RetrieveBlock
The MemoryTree::RetrieveBlock method searches for a tree node associated with a memory block suitable for the requested size. Note that suitable means the block size should be greater than or equal to the requested size. In other words, we perform a lower-bound search. If the node is found, it is removed from the tree and returned as a memory block. Here is the implementation:
1
2
3
4
5
6
7
8
9
10
11
12
MemoryBlock *MemoryTree::RetrieveBlock(size_t size) noexcept {
if (TreeNode *v = LookupNode(size, true)) {
if (v->same_size_nodes) {
TreeNode *same_size_node = v->same_size_nodes;
v->same_size_nodes = same_size_node->same_size_nodes;
return MemoryBlock::FromUserMemory(same_size_node);
}
DetachNode(v);
return MemoryBlock::FromUserMemory(v);
}
return nullptr;
}
One small addition: before removing the found node, we should check the node linked list. If it contains another node with the same size, we retrieve the node from the linked list rather than from the tree.
SimpleAllocator with MemoryTree
Now it’s time to use MemoryTree in SimpleAllocator. Just add a new MemoryTree field to the class.
1
2
3
4
5
6
7
class SimpleAllocator : SimpleAllocatorBase {
public:
// ...
private:
// ...
MemoryTree memory_tree_;
}
SimpleAllocator::Deallocate with MemoryTree
Let’s use the memory tree in the Deallocate() method.
1
2
3
4
5
6
7
8
9
void SimpleAllocator::Deallocate(void *ptr) noexcept {
// ...
auto *memory_block = MemoryBlock::FromUserMemory(ptr);
// ...
// If possible, extend the main buffer by the memory block and return
// If possible, add the memory block to the slot table and return
// ...
memory_tree_.InsertBlock(memory_block);
}
It is pretty straightforward - if we cannot extend the main buffer by the deallocating memory block, or if the deallocating memory block is too big for the slot table, we add it to the memory tree.
SimpleAllocator::Allocate with MemoryTree
The Allocate() method becomes more complicated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void *SimpleAllocator::Allocate(size_t size) noexcept {
// ...
if (slot_index < slots_.size()) {
// ...
// Try to get the memory block from the slot table
// ...
} else if (MemoryBlock *memory_block = memory_tree_.RetrieveBlock(size)) {
const size_t total_left_size = memory_block->GetBlockSize() - size;
if (total_left_size > sizeof(MemoryBlock)) {
const size_t user_left_size = total_left_size - sizeof(MemoryBlock);
if (GetSlotIndex(user_left_size) >= slots_.size()) {
memory_block->SetBlockSize(size);
auto left_memory_block = new (memory_block->UserMemoryEnd()) MemoryBlock{user_left_size};
memory_tree_.InsertBlock(left_memory_block);
}
}
return memory_block->UserMemoryBegin();
}
// ...
// Allocate from the main buffer
// ...
}
Let’s try to understand what’s going on here. As mentioned earlier, MemoryTree::RetrieveBlock returns the memory block using a lower bound lookup. This means that the found memory block has the requested size or is greater. For example, if the memory tree contains only two memory blocks with sizes of 1MB and 10MB, and we need to allocate 2MB, MemoryTree::RetrieveBlock will return the 10MB memory block. We could return the 10MB memory block to the user, but it would be excessive since the user only needs 2MB. Instead, we update the memory block to the requested size, trim the excess, and insert the trimmed portion back into the memory tree.
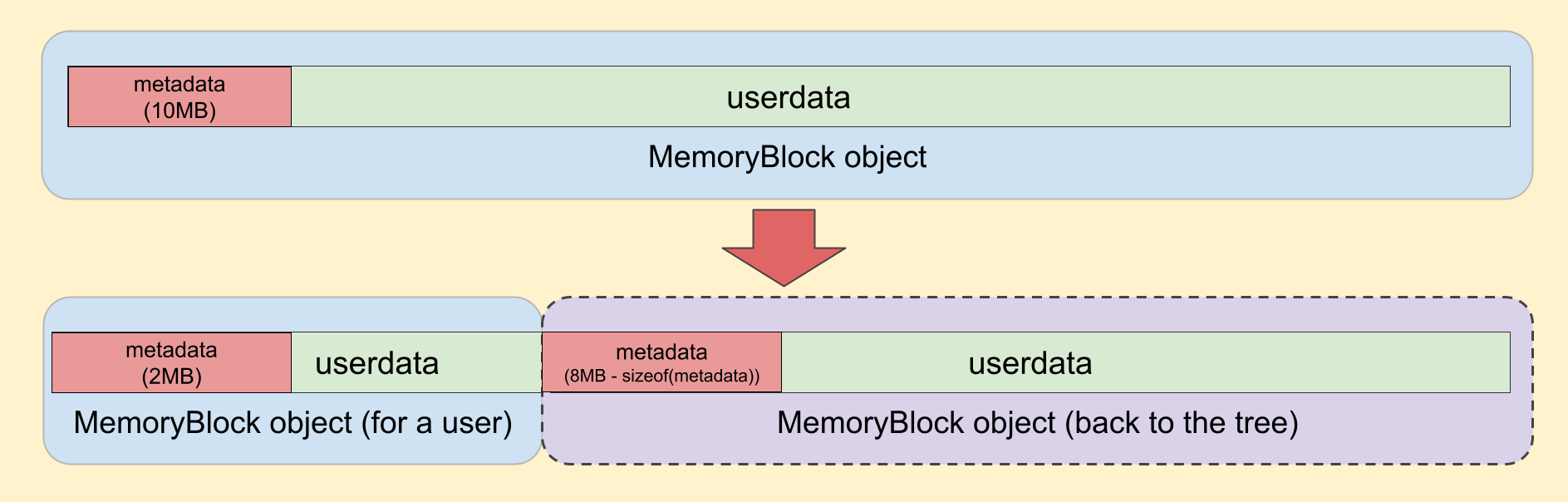 Split the memory block
Split the memory block
Another consideration is that we do not trim the memory block if the trimmed portion is not intended to be stored in the memory tree. This is done in order to avoid unnecessary memory fragmentation.
For example, if the user requests 16400 bytes, and we retrieve a memory block for 16464 bytes, after trimming the excess (taking into account the metadata size), we will have a memory block for 48 bytes (16464 - 16400 - sizeof(MemoryBlock::metadata)). This block is meant to be stored in the slot table. Instead of inserting it into the slot table, we leave the memory block for 16464 bytes as is and return it to the user.
That’s all. The allocator is now complete. Now it’s benchmarking time!
Benchmarks
I don’t want to compare bare std::malloc, std::realloc, and std::free with SimpleAllocator because SimpleAllocator will be much faster in such benchmarks. Instead, I want to compare how the allocator affects STL containers.
For benchmarking, I completely replace the system malloc family. Since I have a macOS, for replacement, I use dyld interposing. I do not post the code here because it is not directly related to the topic, and this trick is specific to macOS. However, if you’re interested in how it is done, you can find the details in Malloc.cpp.
The benchmarks were conducted on a MacBook Pro 2019 with a 2.3 GHz 8-Core Intel Core i9 processor.
Keep in mind that the benchmark plots use a logarithmic scale for both the time and element axes.
Benchmark plots are interactive; you may hide any scenario if you want.
std::vector<int64_t>
Let’s compare push_back().
| Elements | push_back() |
|---|---|
| 1024 | 1.8 us | 2.6 us |
| 2048 | 2.3 us | 3.2 us |
| 4096 | 3.2 us | 4.2 us |
| 8192 | 5.2 us | 6.3 us |
| 16384 | 9.4 us | 10.7 us |
| 32768 | 18.6 us | 19.6 us |
std::vector::push_back() with SimpleAllocator works a bit faster. This difference is not too big because std::vector::push_back() has an amortized constant runtime, which means it doesn’t reallocate the internal array on each push_back(). That’s why even such a small performance boost looks good.
std::deque<int64_t>
Let’s take a look at std::deque<int64_t>. I made several benchmark scenarios.
| Elements | push_back() | pop_front() | push_back() + pop_front() |
|---|---|---|---|
| 1024 | 2.4 us | 3.0 us | 1.6 us | 1.8 us | 3.1 us | 3.4 us |
| 2048 | 3.6 us | 4.6 us | 2.0 us | 2.5 us | 4.4 us | 5.5 us |
| 4096 | 5.8 us | 7.9 us | 2.7 us | 3.8 us | 7.5 us | 9.6 us |
| 8192 | 10.3 us | 14.2 us | 4.0 us | 6.2 us | 13.9 us | 18.2 us |
| 16384 | 19.2 us | 27.1 us | 6.8 us | 11.2 us | 25.7 us | 35.2 us |
| 32768 | 36.6 us | 53.4 us | 12.5 us | 21.0 us | 50.5 us | 68.8 us |
The same story applies as with std::vector<int64_t> — there is a small performance boost because std::deque<int64_t> doesn’t reallocate the internal storage on every push_back() and doesn’t deallocate the internal storage on every pop_front().
std::list<int64_t>
The next benchmark is for std::list<int64_t>. It involves the same scenarios as for std::deque<int64_t>.
| Elements | push_back() | pop_front() | push_back() + pop_front() |
|---|---|---|---|
| 1024 | 6.9 us | 26.3 us | 5.9 us | 34.0 us | 8.6 us | 39.9 us |
| 2048 | 12.5 us | 51.8 us | 10.8 us | 67.9 us | 16.3 us | 78.4 us |
| 4096 | 24.1 us | 103.4 us | 21.3 us | 134.9 us | 33.5 us | 156.8 us |
| 8192 | 51.1 us | 203.7 us | 41.0 us | 274.0 us | 68.9 us | 316.4 us |
| 16384 | 93.0 us | 408.9 us | 85.4 us | 547.7 us | 152.4 us | 638.8 us |
| 32768 | 186.9 us | 812.9 us | 148.5 us | 1084.2 us | 348.1 us | 1276.4 us |
Well, now the difference is much more visible. The benchmarks reveal that methods of std::list<int64_t> with SimpleAllocator are almost 5 times faster compared to using the system malloc. This occurs because std::list<int64_t>, unlike std::vector<int64> and std::deque<int64>, performs an allocation on each push_back() call and a deallocation on each pop_front() call.
std::list<std::string>
Let’s conduct another benchmark, but this time, instead of simple int64_t, we’ll use large std::string objects with sizes greater than 16KB. This will prompt SimpleAllocator to utilize the memory tree.
| Elements | push_back() | pop_front() | push_back() + pop_front() |
|---|---|---|---|
| 1024 | 543.2 us | 3569.2 us | 30.9 us | 1504.1 us | 548.1 us | 1031.8 us |
| 2048 | 1727.3 us | 9743.8 us | 135.5 us | 3196.7 us | 1885.8 us | 4147.5 us |
| 4096 | 3770.5 us | 23369.3 us | 328.4 us | 5267.2 us | 4209.9 us | 13091.0 us |
| 8192 | 8599.2 us | 58418.5 us | 696.6 us | 12642.3 us | 10105.8 us | 32339.7 us |
| 16384 | 21685.6 us | 120360.0 us | 1455.6 us | 28169.7 us | 24767.0 us | 74833.7 us |
| 32768 | 70585.9 us | 268069.0 us | 2985.3 us | 70063.7 us | 84584.5 us | 168244.0 us |
Now the difference is much more visible due to an additional allocation for copying a string and an extra deallocation for destroying a string. It seems that the memory tree works pretty fast.
std::map<int64_t, int64_t>
Another interesting case involves associative containers. I made different scenarios for them, so let’s take a look.
| Elements | insert() | erase() | insert() + erase() |
|---|---|---|---|
| 1024 | 28.8 us | 49.2 us | 16.9 us | 57.1 us | 44.5 us | 79.2 us |
| 2048 | 60.3 us | 102.0 us | 31.9 us | 111.1 us | 99.7 us | 166.3 us |
| 4096 | 127.8 us | 221.3 us | 64.0 us | 221.5 us | 216.3 us | 360.1 us |
| 8192 | 268.1 us | 490.6 us | 122.4 us | 439.5 us | 473.7 us | 763.3 us |
| 16384 | 568.8 us | 1002.4 us | 245.7 us | 801.9 us | 1020.5 us | 1573.7 us |
| 32768 | 1222.8 us | 2354.8 us | 522.7 us | 1564.6 us | 2218.1 us | 3261.7 us |
std::map<int64_t, int64_t> behaves similarly to std::list<int64_t>: with every insert(), it performs an allocation, and with every erase(), it performs a deallocation. The difference lies in the additional tree operations of std::map<int64_t, int64_t>, which have a runtime of O(log(N)). Consequently, the performance improvement is less significant compared to std::list<int64_t>. However, std::map<int64_t, int64_t> with SimpleAllocator still exhibits faster performance, which is favorable.
std::unordered_map<int64_t, int64_t>
This is the final benchmark for SimpleAllocator, where I use std::unordered_map<int64_t, int64_t>, with scenarios similar to those of std::map<int64_t, int64_t>.
| Elements | insert() | erase() | insert() + erase() |
|---|---|---|---|
| 1024 | 17.5 us | 42.5 us | 10.7 us | 38.9 us | 28.2 us | 61.6 us |
| 2048 | 35.9 us | 80.8 us | 19.8 us | 78.6 us | 55.0 us | 127.1 us |
| 4096 | 69.0 us | 153.8 us | 37.4 us | 162.5 us | 114.7 us | 233.9 us |
| 8192 | 147.1 us | 331.3 us | 68.6 us | 357.8 us | 219.7 us | 492.6 us |
| 16384 | 300.3 us | 606.0 us | 143.5 us | 674.3 us | 442.7 us | 975.7 us |
| 32768 | 569.6 us | 1282.3 us | 265.4 us | 1327.1 us | 908.8 us | 1928.0 us |
The performance boost is more significant than in the std::map<int64_t, int64_t> benchmark because the hash table operations have better runtimes, and they affect the insert() and erase() methods less.
What’s next?
Well, the benchmarks show that using SimpleAllocator gives a performance boost, and this is great. However, there are several features that I didn’t implement to avoid overcomplexity. Nevertheless, it is worth considering adding these features to SimpleAllocator.
Metrics
I didn’t add any metrics to SimpleAllocator, but it would be very handy to know
- the main buffer size,
- how much memory is allocated,
- how much memory is available,
- how much memory is wasted due to metadata and alignment,
- etc.
Address sanitizer support
Using SimpleAllocator reduces the effectiveness of the Address Sanitizer because the allocator operates with a preallocated buffer, making it impossible to perform certain Address Sanitizer checks, such as heap buffer overflow, memory usage after free, double free, etc.
To mitigate these issues, we could use Address Sanitizer manual poisoning. This feature allows making memory regions inaccessible. We could poison:
- memory around the main buffer,
- memory around a
MemoryBlockobject, MemoryBlock::metadatabefore returning the memory pointer to a user,- unused user memory in a
MemoryBlockobject after storing it into the slot table or memory tree, - etc.
Memory defragmentation
Prolonged usage of SimpleAllocator may lead to fragmentation of the main buffer. This can result in the inability to allocate a large contiguous memory block, even if the allocator has enough memory available, due to the memory being split by the slot table and memory tree nodes. The simplest solution to this issue is to perform eventual defragmentation. The algorithm is straightforward:
- collect all
MemoryBlockobjects from the slot table and memory tree, - sort them by their addresses,
- and merge adjacent memory blocks.
Additionally, if we want to reuse the defragmented memory block as the main buffer, similar to the source of memory, some logic around the main buffer should be updated. For example, we could introduce pointers to the active buffer and use them instead of current_, buffer_begin_, and buffer_end_.
While this approach may not be optimal, it is functional and can extend the usage time of the allocator before it starts returning nullptr due to out of memory conditions. Feel free to explore alternative solutions.
Multithreading
Well, it is clear that SimpleAllocator cannot be used from different threads simultaneously. Of course, we could use std::mutex and lock every access to SimpleAllocator, but this would make the allocator extremely slow. Can it be better? Probably. The main buffer pointers can be replaced with atomics. The slot table lists can be replaced with lock-free forward lists. However, I’m not sure what to do with the memory tree. You may find some implementations of concurrent binary search trees on the internet, but I’m not sure if they can be adapted for SimpleAllocator. Nevertheless, this is a very interesting challenge to solve. Feel free to try different approaches, but don’t forget about benchmarks; lock-free data structures come with their own costs.
Generally speaking, that’s why the system malloc is less performant than SimpleAllocator, because it concerns itself with memory fragmentation and works perfectly from different threads. SimpleAllocator, on the other hand, ignores that and gains a performance benefit.